Last time I posted I was still months away from having a baby, now I have a four month old. Time to get back into blogging. I have some things specifically about babies and being a working mother and so on, but those will have to wait.
A few weeks ago I asked around on Twitter about creating leaderboards, but couldn’t find a lot out there that worked for exactly what I needed. I was trying to make a simple application for a staff summer reading program that would allow participants to register the pages they’ve read and leave reviews, but without a lot of bureaucracy and overhead. The main tool I found was Leaderboarded, which was interesting, but way too much for the very simple thing I was trying to do. While I could have created a form on our website using Drupal or one of our PHP forms, I figured that the much easier solution would be to use a Google Form, since otherwise it would have been very difficult for the people running the program to monitor participation unless I built an entire web application, which was overkill for a temporary program.
After poking around a bit, I found this super simple solution from David Hay at the Elk Island Public Schools (in Alberta!) Technology blog. Create a form in Google Forms that asks for a name, and then any points to which the student is entitled. Then use pivot tables with the spreadsheet to get totals, and use charts to visualize these. This was very simple, and I also appreciated his script that copies formulas to the last row of the spreadsheet as people add new entries. This of course assumes you have a unique key of a person’s name added the same way each time, which for a small group of people for a short amount of time is probably a reasonable assumption.
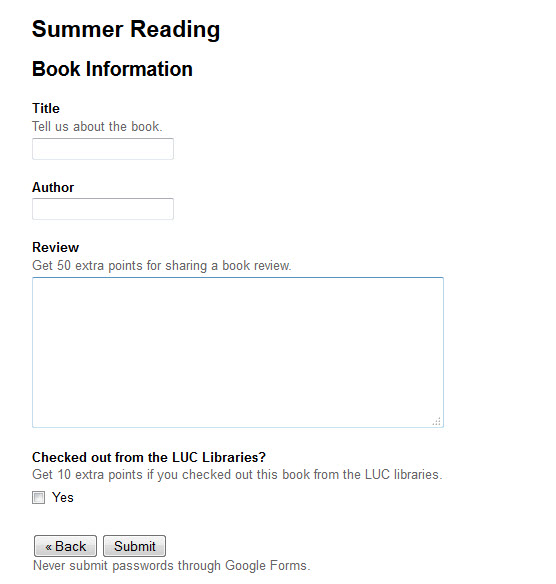
Here’s what I ended up with. You won’t be able to complete the form without Loyola email address (to hopefully prevent spam), but here’s what happens. Most of the time people will just be entering the pages they read last, and won’t need to add anything else. They will fill in that information, and then submit the form. But if they’ve finished a book, they can leave a review for more points. Clicking the “Did you finish a book?” radio button will take them to page 2, which is below. They can fill in author and title only, or add a review for 50 points. They also get an additional 10 points for checking the book out of the LUC libraries.
On the back end, this form records to a spreadsheet. The points are added up in an additional column I added to the spreadsheet. It adds in additional points for the challenges to the pages read using conditionals, which I’d not really used in Google Forms before. They work just as you would expect.
=C2 [pages read]+(if(J2[LUC libraries]="Yes",10[condition if true],0[condition if false])+if(isblank(I2)[review box],0[condition if true],50[condition if false))
Then I use a series of pivot tables and charts to add up the total points for each person (which we will use internally for entering participants in a raffle and determining the overall winner) and departmental points, which we will use to cheer on departments and try to make them compete against each other. To check for the individuals who are ahead, I use a pivot table with a row grouped by name with the sum of total points, and the same thing for departments. Then I made a bar graph sorted by total to make a departmental leaderboard to post on the website, which you can see here (as of publication it’s blank since the program hasn’t started yet).
Since everything is stored in an online form, the group who is running this program will be able to make edits to the form and the data if they need to, and copy the reviews out of the spreadsheet to post on the library’s blog. Very simple, and not using a database when a spreadsheet will do!
Ahem.
.@FakeLibStats : 65% of librarians use a spreadsheet for what can be better and more easily accomplished by a database.
— Roy Tennant (@rtennant) May 8, 2014
